Amazon’s Cloud Service Outage Hits Internet: Current Status and Insights

Introduction
Amazon Web Services (AWS) stands as a cornerstone of the global internet infrastructure, powering a significant portion of websites, applications, and business operations worldwide. Given AWS’s dominant market share-approximately 33% of global cloud infrastructure as of 2024-any disruption in its services can ripple across the internet, impacting millions of users and countless enterprises. This reality underscores the critical importance of cloud service reliability, as businesses and consumers alike increasingly depend on uninterrupted access to cloud-hosted resources.
In this article, we delve into the recent developments surrounding AWS outages, analyze their technical causes, and explore the broader implications for the internet ecosystem. We also provide guidance on monitoring outages through official channels and discuss strategies to mitigate risks associated with cloud service downtime.
Recent Developments (2024-2025)
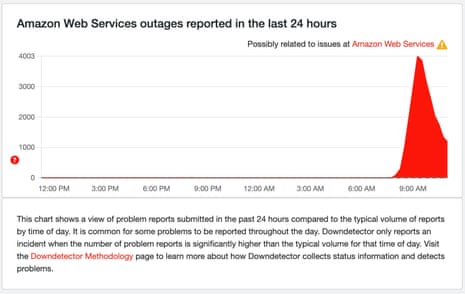
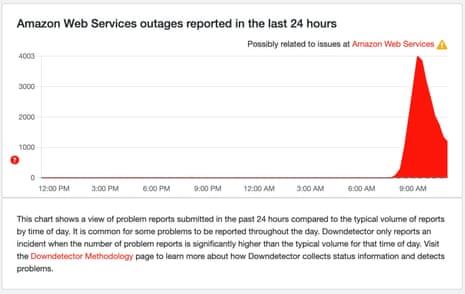
As of late 2024 and into 2025, the AWS Health Dashboard-a primary source for real-time status updates-shows no record of a major, internet-wide Amazon cloud service disruption in recent months. While AWS does experience localized or service-specific outages occasionally, these incidents have not escalated to a level that has caused widespread internet outage impact akin to historical events.
Historically, AWS outages have caused significant disruption. For example, in past years, outages affecting critical services like Amazon S3 and Route 53 led to substantial website downtime for major platforms, highlighting the systemic importance of AWS. These events have spiked public and industry interest in understanding the reliability of cloud service providers and the cascading effects outages can have.
Understanding AWS Outages
AWS outages refer to any interruption in the availability or performance of Amazon Web Services’ cloud infrastructure. These can range from service-specific outages-where particular services like EC2 or DynamoDB are affected-to widespread disruptions impacting multiple regions and service lines.
AWS communicates these incidents through its official channels, primarily the AWS Health Dashboard and social media accounts, providing real-time updates on affected services and estimated resolution timelines. This transparency is vital for IT professionals, business owners, and developers who rely on timely information to mitigate the impact of an outage.
Current Impact of AWS Outages
When an AWS outage occurs, the effects can be immediate and far-reaching. Websites and applications hosted on AWS infrastructure may experience unavailability or degraded performance, directly affecting end-users. For businesses, this translates into lost revenue, diminished customer trust, and operational disruptions.
IT professionals and sysadmins often face intense pressure during such outages to diagnose, communicate, and implement workarounds. Past case studies, such as the notable 2020 AWS S3 outage, demonstrated how even a partial cloud service downtime can cascade into widespread website disruptions and service failures across multiple industries.
For developers, outages might mean interrupted API calls, delayed deployments, or compromised data access, complicating development workflows and user experience consistency.
Technical Causes of AWS Outages
AWS outages typically stem from a combination of factors including infrastructure failures, software bugs, human errors, or external attacks such as Distributed Denial of Service (DDoS) incidents. For instance, misconfigurations in network routing or cascading hardware failures can trigger widespread service disruption.
Experts emphasize that while AWS designs its infrastructure with multiple redundancies, the complexity of cloud environments means that even minor errors can escalate quickly. Software bugs that impact load balancers or failover mechanisms also contribute to outages.
Preventing outages requires continual investment in resilient architecture, robust testing, and automated failover systems. Industry specialists recommend adopting fault-tolerant designs and regularly updating incident response protocols to minimize downtime.
Official Communications from Amazon
The AWS Health Dashboard remains the authoritative source for monitoring AWS outage status and updates. It provides granular information about affected services, regions, and estimated restoration times, enabling stakeholders to stay informed in real-time.
Amazon’s official communication strategy during outages includes detailed post-mortem reports that outline root causes and corrective measures, fostering transparency and trust. Following AWS’s official channels on social media and subscribing to status notifications are essential best practices for IT teams and businesses to maintain situational awareness during disruptions.
Historically, AWS’s clear and timely updates have helped mitigate confusion, allowing affected parties to plan contingencies and communicate effectively with their customers.
Alternative Services and Backup Strategies
Given the inevitability of occasional cloud service downtime, many organizations explore alternative cloud service providers such as Microsoft Azure, Google Cloud Platform, and IBM Cloud to diversify their infrastructure. This multi-cloud strategy helps reduce dependency on a single provider and enhances resilience.
Best practices for mitigating the impact of Amazon cloud service disruption include implementing automated failover systems, maintaining backups in geographically diverse data centers, and designing applications for graceful degradation during outages.
Cloud service downtime can be minimized by leveraging containerization and orchestration tools like Kubernetes, which facilitate rapid re-deployment across different cloud platforms, ensuring business continuity.
Community Discussions and Shared Solutions
During AWS outages, community forums such as Reddit, Hacker News, and Twitter become vital hubs for real-time information exchange and troubleshooting collaboration. These platforms enable IT professionals, developers, and enthusiasts to share experiences, workarounds, and updates on the impact of AWS outage on websites and services.
Participating in these discussions can provide valuable insights and alternative perspectives not always available through official channels. Collaborative problem-solving has resulted in innovative solutions during past outages, such as temporary DNS rerouting and alternative API endpoints.
Engaging with these communities also helps businesses gauge the broader impact of outages and adapt their communication strategies accordingly.
Future Trends in Cloud Service Reliability
The cloud computing industry is actively pursuing emerging technologies to enhance service resilience. Artificial Intelligence (AI) and automation are increasingly employed for proactive incident detection, real-time anomaly analysis, and rapid remediation, reducing the window of impact during outages.
Regulatory bodies are also expected to introduce stricter transparency and reliability standards for cloud providers, motivating continuous improvements in infrastructure robustness and customer communication.

Innovations such as decentralized cloud architectures and edge computing promise to distribute workloads more effectively, mitigating risks of centralized failures and improving overall internet stability.
Conclusion
AWS continues to be a pillar of internet reliability, yet the potential for outages remains an inherent risk given its vast scale and complexity. Understanding the causes, impacts, and mitigation strategies associated with AWS outage events is crucial for IT professionals, business owners, and developers who rely on cloud infrastructure.
Preparing for cloud service disruptions involves monitoring official updates, adopting multi-cloud and backup strategies, and engaging with community resources to navigate outages effectively. As cloud dependency grows, proactive resilience planning will be key to minimizing downtime and safeguarding digital operations in the future.
By staying informed and implementing best practices, businesses and individuals can better withstand the challenges posed by any future Amazon’s Cloud Service Outage incidents, ensuring continuity and trust in their online presence.